vert.x 学习
动手实践
生成代码
vert.x 官方提供了一个生成代码的在线工具:https://start.vertx.io/
打开后,简单配置一些信息,然后选择依赖,假设我们是第一次使用,想做的就是和开发 Spring Boot 一样的返回 json 的接口,那么只需要选择 Vert.x Web 依赖:
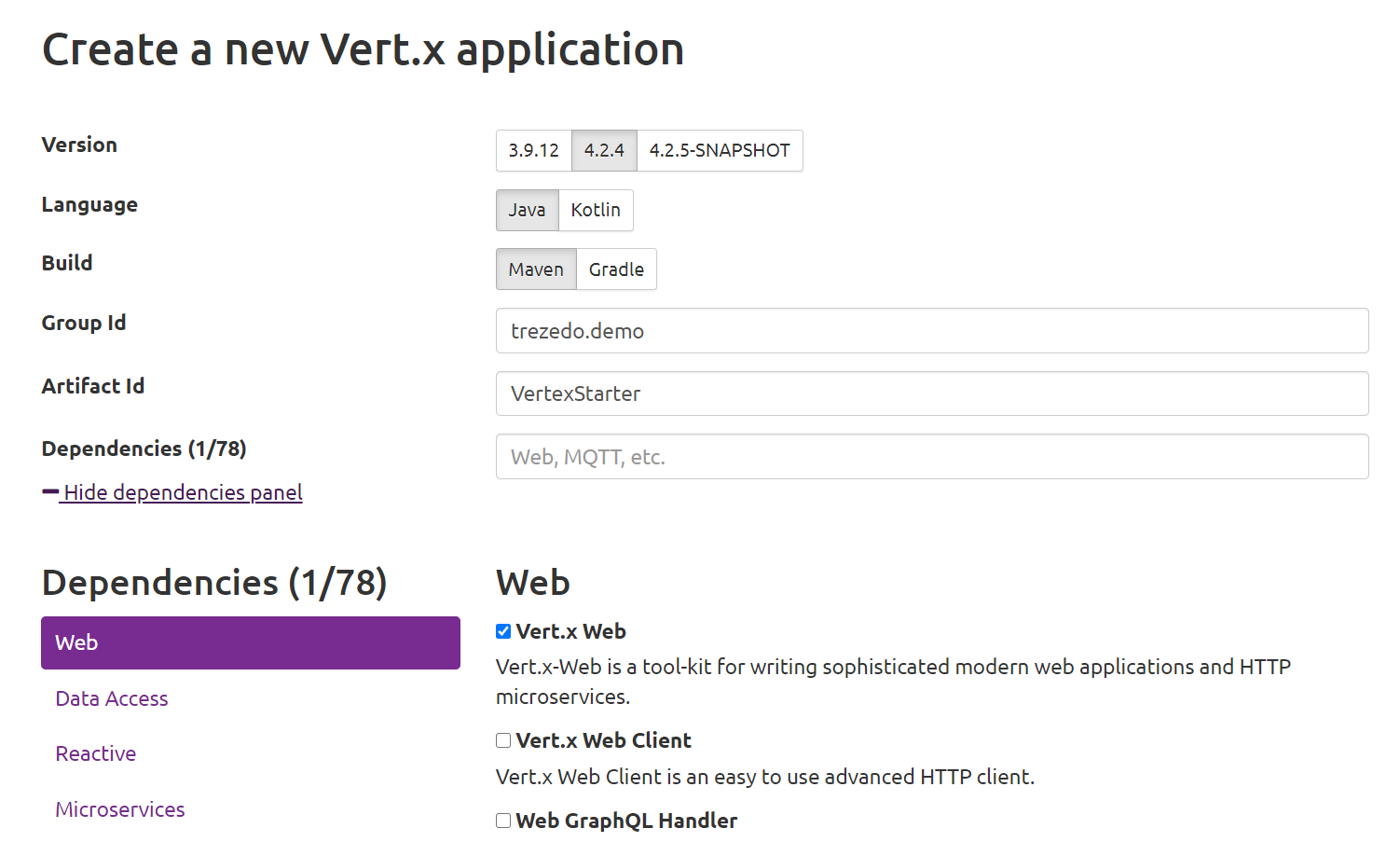
当然,通常我们的项目是需要数据库的,Vert.x 提供了 PostgreSQL、MySQL、MSSQL、Oracle、MongoDB、Redis 等常见数据库的客户端:
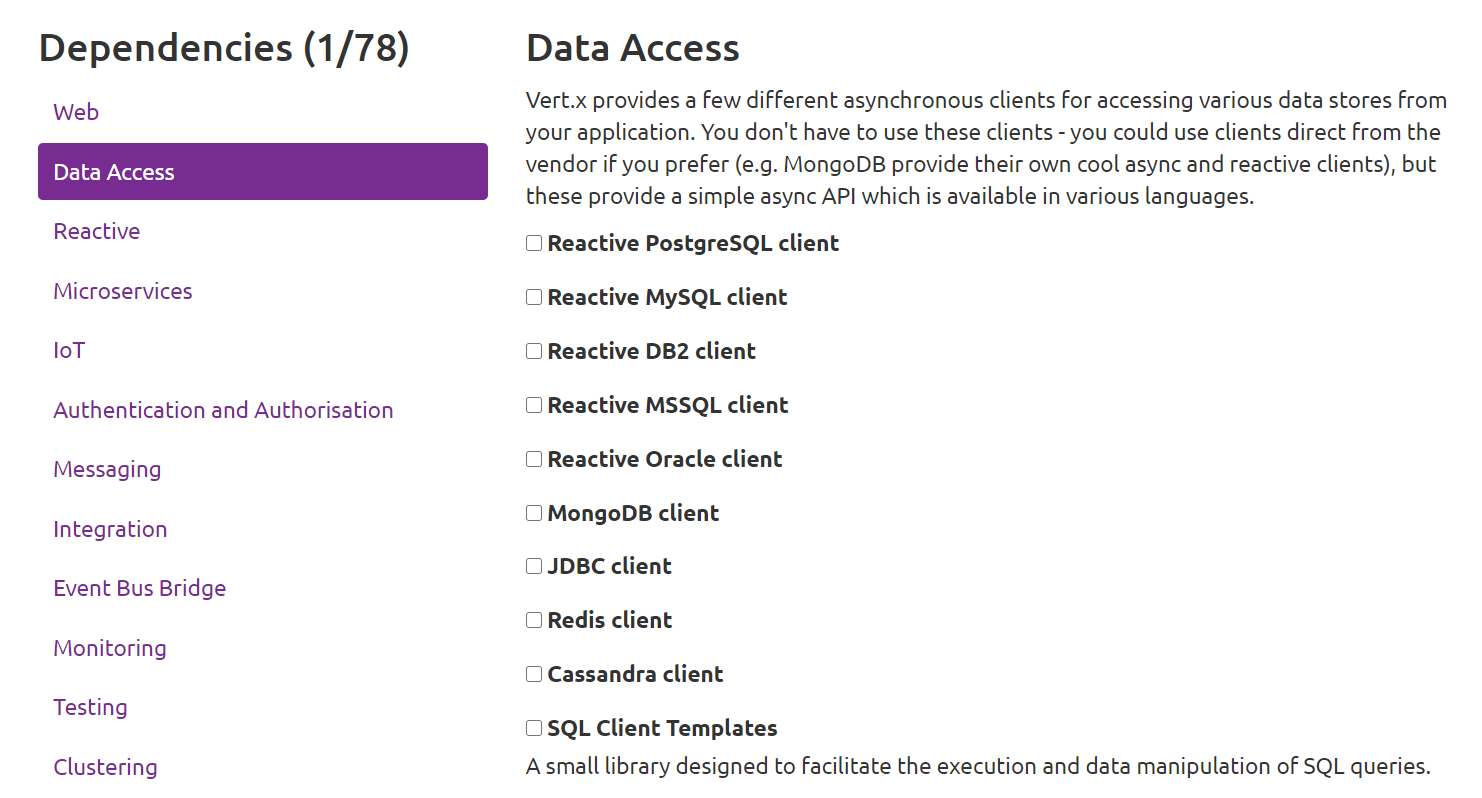
根据你们所使用的数据库选择对应的客户端即可。本人常用 PostgreSQL,因此这里选择它的客户端。
Vert.x 默认生成的代码默认使用的是 JDK 11,相信大多数开发者安装的版本还是 JDK 1.8(或者 JDK 8,两者是一个东西),因此还需要修改版本,点击 Advanced options,选择 JDK 1.8:
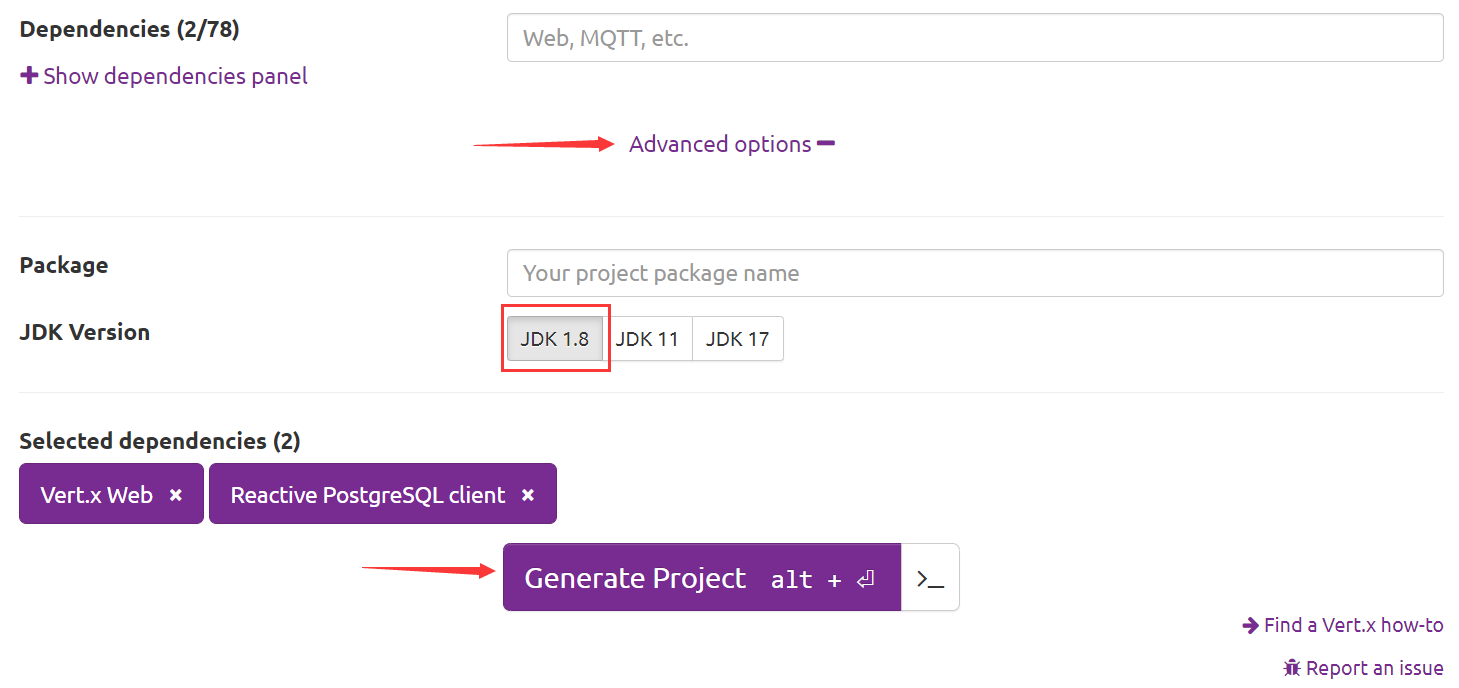
然后点击 Generate Project 等待生成代码完毕,随后会让你下载一个压缩包文件。
提示
如果很久都没有生成好,刷新一下页面即可。
配置文件
解压刚才下载的压缩包到某个空目录,这样就是一个 Vert.x 项目了。然后用 Java 的 IDE 打开这个项目文件夹,这里我用的是 IntelliJ IDEA。首先需要打开的是根目录下的 pom.xml 文件,它是一个 maven 项目的配置文件,看看是否有报错,这个报错通常是正常的,因为我们还没有下载依赖。解决办法也很简单,只需要简单调整一下该文件的依赖顺序,然后右上角会出现这个按钮:
点击它就会加载 maven 变更,如果没有的依赖它就会自动从 maven 中心下载(当然,我们也可以剪切一部分依赖,然后加载变更,再把剪切掉的粘贴回来,再次加载变更即可)。
提示
一个依赖的结构通常是这样的:
<dependency>
<groupId>包结构</groupId>
<artifactId>项目名</artifactId>
<version>版本号</version>
</dependency>如果遇到 maven plugin 报错(提示找不到依赖)的情况,可能是因为 IDE 没能正确识别,加上 groupId 即可:
<plugin>
+ <groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>${maven-surefire-plugin.version}</version>
</plugin>如果遇到其他问题,请自行搜索😂。
如何运行
假设到这里为止,项目中的 pom.xml 已经没有报错了,那么就可以去看 java 代码了。
根据刚才我的配置,生成的项目中 src 目录的结构是这样的:
.
└─src
├─main
│ └─java
│ └─trezedo
│ └─demo
│ └─VertxStarter
│ MainVerticle.java
└─test
└─java
└─trezedo
└─demo
└─VertxStarter
TestMainVerticle.java让我们来看 MainVerticle.java:
package trezedo.demo.VertxStarter;
import io.vertx.core.AbstractVerticle;
import io.vertx.core.Promise;
public class MainVerticle extends AbstractVerticle {
@Override
public void start(Promise<Void> startPromise) throws Exception {
vertx.createHttpServer().requestHandler(req -> {
req.response()
.putHeader("content-type", "text/plain")
.end("Hello from Vert.x!");
}).listen(8888, http -> {
if (http.succeeded()) {
startPromise.complete();
System.out.println("HTTP server started on port 8888");
} else {
startPromise.fail(http.cause());
}
});
}
}通过阅读这段代码,我们大致可以知道:
vertx 实例创建了一个 Http 服务,它对一个请求(request)的处理(handle)是,响应(response)一段内容类型(content-type)为普通文本(text/plain),以 "Hello from Vert.x!" 结束这个请求。并且这个 vertx 实例会监听(listen)8888 号端口,如果成功启动服务,则会打印 "HTTP server started on port 8888"。
为了验证以上是否正确,最好的办法当然是把这个项目跑起来。在根目录下,其实有个 README.adoc 文件,它说:
To launch your tests:
./mvnw clean testTo package your application:
./mvnw clean packageTo run your application:
./mvnw clean compile exec:java
但是我实际操作后发现没任何反应,官网说的东西居然不能用?
事实上,简单阅读根目录下的 mvnw 和 mvnw.cmd 文件后可以发现,它们分别是 linux 和 windows 系统的脚本,也就是说,如果电脑本机安装了 maven,它们是可以正常运行的,而此处我使用的 IDEA 内嵌的 maven,自然运行之后是没有反应的。
vert.x 难道没有像 SpringBoot 项目一样有一个 main 方法来启动项目吗?
其实是有的,但官网却没有在显眼的地方说清楚:
// MainVerticle.java
public static void main(String[] args) {
Vertx.vertx().deployVerticle(new MainVerticle());
}提示
部署一个 Verticle 的方法,在 deploying verticles programmatically 是有说明的,但是对于一个刚入门的开发者而言,这藏的还挺深🙄。
当然,开发环境下部署 (deploy) 的方法不止这一种“方法”。
其他部署方法
要知道,多态是 Java 这种面向对象语言的一大特性,deployVerticle 有多种同名方法,还可以使用如下方法部署:
Vertx vertx = Vertx.vertx();
/* 通过类名运行 */
vertx.deployVerticle("trezedo.demo.VertxStarter.MainVerticle");
vertx.deployVerticle(MainVerticle.class.getName()); // 推荐
/* 添加 handler */
vertx.deployVerticle(MainVerticle.class.getName(), result -> {
if (result.succeeded()) {
System.out.println("Deployment id : " + result.result());
} else {
System.out.println("Deployment failed!");
try {
throw result.cause();
} catch (Throwable e) {
e.printStackTrace();
}
}
});通常情况下,使用第 5 行的就够了;如果希望增强,例如输出错误原因(端口占用等),那么可以用 8-19 行的方式。
添加这个 main 方法后,就可以运行了,可以通过浏览器打开 http://localhost:8888 查看是否成功:
这和我们在 上面 所说的结果看上去是一致的。
第一个接口
Vert.x 通过路由 Router 来管理 Route(可以理解为一个 url 请求),通常每个 Verticle 只有一个 vertx 实例。现在我们来创建第一个接口:
public void start(Promise<Void> startPromise) {
Router router = Router.router(vertx); // 创建 router 实例
router.route("/api/hello").handler(routingContext -> {
JsonObject json = new JsonObject();
json.put("code", 200);
json.put("msg", "success");
json.put("data", new JsonArray("[\"2022\", \"vert.x\", \"你好\"]"));
List<String> data2 = new ArrayList<>();
data2.add("2021");
data2.add("goodbye");
data2.add("再见");
json.put("data2", new JsonArray(data2));
routingContext.response()
.putHeader("content-type", "application/json;utf-8")
.end(json.toString());
});
vertx.createHttpServer().requestHandler(router).listen(8888, http -> {
if (http.succeeded()) {
startPromise.complete();
System.out.println("HTTP server started on port 8888");
} else {
startPromise.fail(http.cause());
}
});
}注意高亮的行,这里的我们把 requestHandler 的参数改成了我们创造的 router(第 19 行),否则所有的请求都会是 "Hello from Vert.x!"。
简单说下代码的含义:
- 第 4 行: 创建了一个类型为
JsonObject的对象,这个是vert.x core中提供的类,除此之外还提供了JsonArray,这两个想必不用太多解释; - 5-7 行:对刚刚创建的对象添加键值对(和
Map类类似),这里用了JsonArray的构造方法:JsonArray(String json); - 9-12 行:创建一个字符串列表并添加数据;
- 第 13 行:在上面的
json对象中添加一个键值对,这里用了JsonArray的构造方法:JsonArray(List list); - 14-16 行:响应一个请求,设置
MIME Type(互联网媒体类型)为application/json,charset为utf-8,并返回之前创建的JsonObject对象。
另外,第 15 行是有必要的。实际上如果没有该行同样能够响应,但是由于我们返回的内容中包含中文,缺少该行会变成乱码!同时,由于没有设置 MIME 类型,部分浏览器的相关插件可能不会正常运作,感兴趣的读者可以自己尝试。
其中,最重要的当属第 16 行,如果没有 response.end() 方法,客户端会一直等待“回复”,导致客户端“阻塞”(只是这个 URL 阻塞,新建一个 tab 访问其他正常的 URL 是没问题的)。
现在重新运行项目,打开浏览器测试一下:
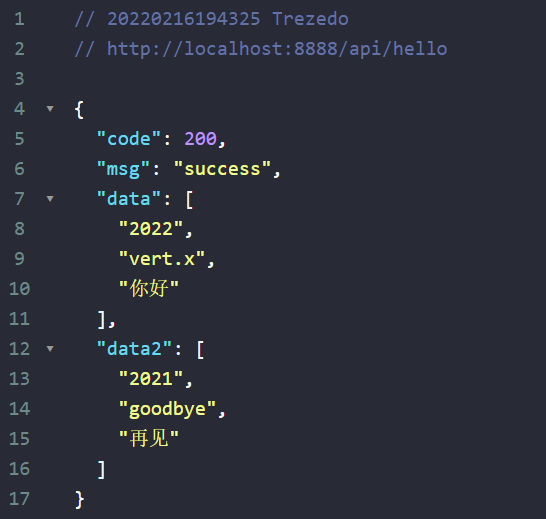
与我们的预期一致,尽管逻辑很简单,这就是我们的第一个接口!
小提示
这里我用了 Chrome 浏览器的插件 JSON Viewer,以便于查看、美化 json,方便截图。
如果插件应用商店链接打不开的,下面有几个好用的插件网站可以下载:
这里也有另一个下载安装方便的插件:JSON-Handle,打开后在页面中找到下载(或者直接点 这里),完成后根据提示添加插件即可。
简单重构
到这里可能有些读者就会想,这么长一串代码,全部放进一个 start 方法里,又臭又长的怎么好管理呢?
别着急,聪明的读者或许已经发现,在 route 的 handler 方法中,它的参数是一个 interface,只不过我们处理的时候用了从 Java8 开始提供的的 lambda 表达式,这意味着我们可以抽离它的逻辑到某个函数当中,只需要这个函数的参数和 handler 方法中接口的参数类型一致就可以了。来动手试试:
public void start(Promise<Void> startPromise) {
Router router = Router.router(vertx);
router.route("/api/hello").handler(routingContext -> {
handleHello(routingContext);
});
// ...
}
private void handleHello(RoutingContext routingContext) {
JsonObject json = new JsonObject();
json.put("code", 200);
json.put("msg", "success");
json.put("data", new JsonArray("[\"2022\", \"vert.x\", \"你好\"]"));
List<String> data2 = new ArrayList<>();
data2.add("2021");
data2.add("goodbye");
data2.add("再见");
json.put("data2", new JsonArray(data2));
routingContext.response()
.putHeader("content-type", "application/json;utf-8")
.end(json.toString());
}可以看到,我们把一个路由的相关逻辑统一放到一个方法中,这样管理和维护起来就会更加方便。实际上,我们的 handleHello 方法中只有一个参数,此时利用 lambda 表达式的特点,上述代码中第 3-5 行可以化简为方法引用:
router.route("/api/hello").handler(this::handleHello);打包
将我们的 vert.x 项目打包成 jar 文件,这与 SpringBoot 项目的打包方式类似,只需要在 IDEA 右侧点击 maven,找到 package,双击即可。

注意
由于打包过程中会进行测试,会在默认的 8888 端口 deploy 一个 Verticle,因此为了打包的顺利进行,需要关闭正在运行的 MainVerticle。
打包完成后,在根目录下找到 target 文件夹,会看到有 xxx.jar 和 xxx-fat.jar(xxx 会根据你的 pom.xml 配置而改变)两个文件,其中后者是可以用命令行直接运行的:
java -jar xxx-fat.jar也就是说,xxx-fat.jar 文件可以拿到服务器上部署。
如果注意看文件大小,会发现 vert.x 生成的文件体积比起 SpringBoot 的小 60%-80% 左右,这点我还是很喜欢的。
对象转换
vert.x 内置了两个 json 工具类:JsonObject 和 JsonArray,方便开发者处理 json,两者均依赖于 jackson。
通过 JsonObject 的构造方法可以将字符串、map 对象、buffer 对象转成 json 对象。
但是如果需要执行以下两种操作,则需要引入 jackson-databind 依赖:
否则会抛出异常:
io.vertx.core.json.DecodeException: Mapping XXX is
not available without Jackson Databind on the classpath既然需要用到 Jackson Databind,那就添加依赖:
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>版本号</version>
</dependency>版本号最好和 vert.x 所使用的一致,但似乎 vert.x 对它的版本没有特殊要求。目前的最新版本是 
值得一提的是,jackson-databind 包的大小约有 1.5MB,如果你在意打包体积,可以使用谷歌的 Gson(276KB)或者阿里巴巴的 FastJson(656KB)。
提示
并不建议使用 Gson 或者 FastJson,因为不论是 vert.x 还是 Spring 都选择了 Jackson。FastJson 曾经多次出现过漏洞(不过更新之后都修复了),而 Gson 的功能是挺强的,但性能相对较弱。
相关对比可以查看:Jackson 替换 fastjson
通常对 json 对象有两种操作:
- 通过
JsonObject.mapTo(Clazz)方法将JsonObject字符串转成Java对象; - 通过
JsonObject.mapFrom(Object)将普通Java对象转成JsonObject;
实际上,上面两种操作就是序列化与反序列化。
序列化
所谓 JSON 序列化,就是将 JAVA 对象转 JSON 字符串。
我们先建一个名为 User 的 Java Bean:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
private String userId;
private String loginName;
private String passwordMd5;
private Date loginDate;
}关于注解
这里的 @Data、@NoArgsConstructor 和 @AllArgsConstructor 都是 lombok 提供的注解,分别用于自动生成 setters 和 getters ,无参构造方法和全参构造方法,这里只是为了方便,不做过多阐述。如果需要使用,添加依赖即可:
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
<scope>provided</scope>
</dependency>然后,我们在 vert.x 项目的 TestMainVerticle 测试类中测试一下:
@Test
void testJava2Json(VertxTestContext testContext) {
testContext.completeNow();
User user = new User(1L, "user1", "pwd_user1", new Date());
JsonObject json = JsonObject.mapFrom(user);
System.out.println(json);
}运行测试,可以看到控制台的结果如下:
{
"userId": 1,
"loginName": "user1",
"password": "pwd_user1",
"loginDate": 1645102775019
}单个 Java Bean 对象和我们预期是一样的,那如果是数组、列表呢?
User user1 = new User(1L, "user1", "pwd_user1", new Date());
User user2 = new User(2L, "user2", "pwd_user2", new Date());
User user3 = new User(3L, "user3", "pwd_user3", new Date());
List<User> userList = Arrays.asList(user1, user2, user3);
User[] users = new User[]{user1, user2, user3};
System.out.println(new JsonArray(userList));
System.out.println(new JsonArray(Arrays.asList(users)));查看输出
[{"userId":1,"loginName":"user1","password":"pwd_user1","loginDate":1645103811786},{"userId":2,"loginName":"user2","password":"pwd_user2","loginDate":1645103811786},{"userId":3,"loginName":"user3","password":"pwd_user3","loginDate":1645103811786}]
[{"userId":1,"loginName":"user1","password":"pwd_user1","loginDate":1645103811786},{"userId":2,"loginName":"user2","password":"pwd_user2","loginDate":1645103811786},{"userId":3,"loginName":"user3","password":"pwd_user3","loginDate":1645103811786}]这里需要注意,因为列表或者数组不是一个 json,因此需要用 vert.x 提供的 JsonArray,而不是 JsonObject。通过结果可以看到,序列化的结果也是我们预期得到的。
使用注解
Jackson 提供了一系列注解,方便对 JSON 序列化和反序列化进行控制,下面介绍一些常用的注解。
- @JsonProperty:用于属性,作用是把该属性的名称序列化为另外一个名称,例如
@JsonProperty("user_id")会把userId属性序列化为user_id。 - @JsonFormat:用于属性,作用是格式化
Date类型数据,如@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")。 - @JsonIgnore:用于属性,作用是进行 JSON 操作时忽略该属性。
为 User.java 类的属性添加注解:
public class User {
@JsonProperty("user_id")
private Long userId;
@JsonProperty("login_name")
private String loginName;
private String password;
@JsonProperty("login_date")
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private Date loginDate;
}重新运行测试:
User user = new User(1L, "user1", "pwd_user1", new Date());
JsonObject json = JsonObject.mapFrom(user);
System.out.println(json);结果如下:
{
"password": "pwd_user1",
"user_id": 1,
"login_name": "user1",
"login_date": "2022-02-17 21:32:37"
}可以看到,新的 json 格式把所有小驼峰命名方式改成了下划线命名方式,这对于日后操作数据库是很有帮助的,因为数据库中使用的 SQL 不区分大小写,那么对于数据库的表名和字段等比较合适的命名方式就是下划线法,使用该注解就可以很方便的与数据库交换数据。
提示
实际上,如果命名规范,可以使用 @JsonNaming 注解,而不用在每个字段上使用 @JsonProperty:
@JsonNaming(PropertyNamingStrategies.SnakeCaseStrategy.class)
public class User {
private Long userId;
private String loginName;
private String password;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private Date loginDate;
}注解的更多使用方式这里不再探讨,请查看文档:jackson-annotations。
反序列化
JSON 反序列化,就是将 JSON 转化为 Java 类。
重要
反序列化需要无参构造方法,否则会抛出 java.lang.IllegalArgumentException 异常。
下面直接给出反序列化一个简单对象的方法:
@Test
void testJson2Java(VertxTestContext testContext) {
testContext.completeNow();
User user = new JsonObject(
"{\"password\":\"pwd_user1\"," +
"\"user_id\":1," +
"\"login_name\":\"user1\"," +
"\"login_date\":\"2022-02-17 21:32:37\"}"
).mapTo(User.class);
System.out.println(user);
System.out.println(user.getUserId());
System.out.println(user.getLoginName());
System.out.println(user.getPassword());
System.out.println(user.getLoginDate());
}查看输出结果
User(userId=1, loginName=user1, password=pwd_user1, loginDate=Thu Feb 17 21:32:37 CST 2022)
1
user1
pwd_user1
Thu Feb 17 21:32:37 CST 2022反序列化复杂对象
通常情况下,“简单对象”指的是非 Map、List 等类型的对象,似乎一直以来 vert.x 提供的 JsonArray 类对复杂对象的支持就不太好。接下来测试:
String jsonStr = "[" +
"{\"password\":\"pwd_user1\",\"user_id\":1,\"login_name\":\"user1\",\"login_date\":\"2022-02-18 13:17:59\"}," +
"{\"password\":\"pwd_user2\",\"user_id\":2,\"login_name\":\"user2\",\"login_date\":\"2022-02-18 13:17:59\"}," +
"{\"password\":\"pwd_user3\",\"user_id\":3,\"login_name\":\"user3\",\"login_date\":\"2022-02-18 13:17:59\"}" +
"]";
JsonArray jsonArray = new JsonArray(jsonStr);
List<User> userList = jsonArray.getList();
System.out.println(userList);到这里为止,估计你会认为没有什么问题,因为它的输出是这样的:
[{password=pwd_user1, user_id=1, login_name=user1, login_date=2022-02-18 13:17:59}, {password=pwd_user2, user_id=2, login_name=user2, login_date=2022-02-18 13:17:59}, {password=pwd_user3, user_id=3, login_name=user3, login_date=2022-02-18 13:17:59}]但是,细心的读者会发现,这个输出的结构不是 User(user_id=...) 这种结构,而更像是 Java 中的 Map。那不妨让我们正真去“用”这个对象:
userList.forEach(System.out::println);果然,报错了:
java.lang.ClassCastException: java.util.LinkedHashMap cannot be cast to trezedo.demo.VertxStarter.entity.User也就是说,实际上 JsonArray 的 getList 方法,并没有正真的转成一个 List,而是使用了 LinkedHashMap 这种数据结构,从而当我们使用它转换的 List 时就会出现问题,这也能说明为什么上面打印的结果是 Map 的结构。
可惜的是,JsonArray 也没有提供可泛化的方法。难道这种对象就没有办法处理了吗?
实际上是有的,那就是返璞归真,只需要注意 JsonArray 通过 Jackson 来实现的这个事实:可以用 Jackson 处理这种对象。回想一下之前用过的 SpringBoot,是不是绝大多数场景下,我们接口中的对象主要是 Java Bean 和 List 的组合?我们直接使用 Jackson 提供的方法来处理就好了!
在上面的例子中,我们可以这样将“复杂对象”反序列化:
ObjectMapper mapper = new ObjectMapper();
try {
List<User> userList = mapper.readValue(jsonStr, new TypeReference<List<User>>() {});
userList.forEach(System.out::println);
} catch (JsonProcessingException e) {
e.printStackTrace();
}ObjectMapper mapper = new ObjectMapper();
JavaType javaType = mapper.getTypeFactory().constructParametricType(List.class, User.class);
// 如果是 Map 类型,用下面的
// mapper.getTypeFactory().constructParametricType(Map.class, String.class, User.class);
try {
List<User> userList = mapper.readValue(jsonStr, javaType);
userList.forEach(System.out::println);
} catch (JsonProcessingException e) {
e.printStackTrace();
}测试结果如下:
User(userId=1, loginName=user1, password=pwd_user1, loginDate=Fri Feb 18 13:17:59 CST 2022)
User(userId=2, loginName=user2, password=pwd_user2, loginDate=Fri Feb 18 13:17:59 CST 2022)
User(userId=3, loginName=user3, password=pwd_user3, loginDate=Fri Feb 18 13:17:59 CST 2022)好了,有关序列化与反序列化的内容就介绍到这里,更多使用细节请自行了解。
路由
Router 是 Vert.x Web 的核心概念之一,它是一个维护了零或多个 Route 的对象。
Router 接收 HTTP 请求,并查找首个匹配该请求的 Route,然后将请求传递给这个 Route。
Route 可以持有一个与之关联的处理器用于接收请求。您可以通过这个处理器对请求做一些事情,然后结束响应或者把请求传递给下一个匹配的处理器。
我们已经在前文:第一个接口 中使用过路由,为了加深印象,这里再给出了一个简单的路由示例:
Router router = Router.router(vertx);
router.route().handler(routingContext -> {
// 所有的请求都会调用这个处理器处理
HttpServerResponse response = routingContext.response();
response.putHeader("content-type", "text/plain");
// 写入响应并结束处理
response.end("Hello from Vert.x!");
});
vertx.createHttpServer().requestHandler(router).listen(8888);和上文一样,我们创建了一个 HTTP 服务器,然后创建了一个 Router。在这之后,我们创建了一个没有匹配条件的 Route,这个 route 会匹配所有到达这个服务器的请求。
之后,我们为这个 route 指定了一个处理器,所有的请求都会调用这个处理器处理。
调用处理器的参数是一个 RoutingContext 对象。它不仅包含了 Vert.x 中标准的 HttpServerRequest 和 HttpServerResponse,还包含了各种用于简化 Vert.x Web 使用的东西。
每一个被路由的请求对应一个唯一的 RoutingContext,这个实例会被传递到所有处理这个请求的处理器上。
处理请求并调用下一个处理器
当 Vert.x Web 决定路由一个请求到匹配的 route 上,它会使用一个 RoutingContext 调用对应处理器。如果不在当前处理器里结束这个响应,则需要调用 next 方法让其他匹配的 Route 来处理请求(如果有):
Route route = router.route();
route.handler(ctx -> {
ctx.response().putHeader("content-type", "application/json;utf-8");
ctx.next();
});为了方便,这里使用缩写 ctx 来代表 RoutingContext。
捕捉路径参数
可以通过占位符声明路径参数并在处理请求时通过 params 方法获取,以下是一个例子:
Route route = router.route(HttpMethod.POST, "/api/users/:userType/:userId");
route.handler(routingContext -> {
String userType = routingContext.request().getParam("userType");
String userId = routingContext.request().getParam("userId");
// 执行其他操作...
});占位符由 : 和参数名构成。参数名由字母、数字和下划线构成。
在上述的例子中,如果一个 POST 请求的路径为 /api/users/vip1/19622,那么会匹配这个 Route,并且会接收到参数 userType 的值为 vip1,参数 userId 的值为 19622。
基于 HTTP Method 的路由
默认情况下,Route 会匹配所有 HTTP Method。如果需要 Route 只匹配指定的 HTTP Method,可以使用 method 方法:
Route route = router.route().method(HttpMethod.POST);
route.handler(ctx -> {
// 所有的 POST 请求都会调用这个处理器
});或者可以在创建这个 Route 时和路径一起指定:
Route route = router.route(HttpMethod.POST, "/some/path/");
route.handler(ctx -> {
// 所有路径为 "/some/path/" 的 POST 请求都会调用这个处理器
});如果想让 Route 指定的 HTTP Method ,您也可以使用对应的 get、post、put 等方法。下面是一个例子:
router.get().handler(ctx -> {
// 所有 GET 请求都会调用这个处理器
});
router.get("/some/path/").handler(ctx -> {
// 所有路径为 `/some/path/` 的 GET 请求都会调用这个处理器
});
router.post("/some/path/").handler(ctx -> {
// 所有路径为 `/some/path/` 的 POST 请求都会调用这个处理器
});如果您想要让一个路由匹配不止一个 HTTP Method,您可以调用 method 方法多次:
Route route = router.route().method(HttpMethod.POST).method(HttpMethod.PUT);
route.handler(ctx -> {
// 所有 GET 或 POST 请求都会调用这个处理器
});子路由
当有很多处理器的情况下,合理的方式是将它们分隔为多个 Router。这也有利于您在多个不用的应用中通过设置不同的根路径来复用处理器。
可以通过将一个 Router 挂载到另一个 Router 的挂载点上来实现。挂载的 Router 被称为子路由(Sub Router)。Sub router 上也可以挂载其他的 sub router,因此我们可以包含若干级别的 sub router。
让我们看一个 sub router 挂载到另一个 Router 上的例子:
这个 sub router 维护了一系列处理器,对应了一个 REST API。我们会将它挂载到另一个 Router 上。 例子忽略了 REST API 的具体实现:
Router restAPI = Router.router(vertx);
restAPI.get("/products/:productID").handler(ctx -> {
// TODO 查找产品信息
rc.response().write(productJSON);
});
restAPI.put("/products/:productID").handler(ctx -> {
// TODO 添加新的产品
rc.response().end();
});
restAPI.delete("/products/:productID").handler(ctx -> {
// TODO 删除产品
rc.response().end();
});如果这个 Router 是一个顶级的 Router,那么例如 /products/product1234 这种 URL 的 GET/PUT/DELETE 请求都会调用这个 API。
如果我们已经有了一个网站包含以下的 Router:
Router mainRouter = Router.router(vertx);
// 处理静态资源
mainRouter.route("/static/*").handler(myStaticHandler);
mainRouter.route(".*\\.template").handler(myTemplateHandler);我们可以将这个 sub router 通过一个挂载点挂载到主 router 上,这个例子使用了 /productAPI:
mainRouter.mountSubRouter("/productsAPI", restAPI);这意味着这个 REST API 现在可以通过这种路径访问:/productsAPI/products/product1234。
更多内容可以查看官方文档的中文翻译,这部分内容也摘自官方文档,不过要注意这个文档是基于 vert.x 3 的,和 4.x 有细微差别。本文在 参考 中给出链接。
数据库
相信大多数开发者都接触过 RDBMS(关系型数据库管理系统),这里我将使用其中的 PostgreSQL 数据库。以下内容主要参考 官方文档。
配置参数
连接数据库,需要配置一些数据库的信息:
// 数据库参数
PgConnectOptions connectOptions = new PgConnectOptions()
.setPort(5432) // 端口号,pgsql默认为5432
.setHost("the-host") // 主机
.setDatabase("the-db") // 数据库名称
.setUser("user") // 登录用户名
.setPassword("secret"); // 登录密码
// 连接池参数
PoolOptions poolOptions = new PoolOptions()
.setMaxSize(5);连接数据库
上面我们只是创建了配置参数的实例,还没有使用。创建一个客户端连接池来连接数据库:
SqlClient client = PgPool.client(connectOptions, poolOptions);池化客户端使用一个连接池,任何操作都会从池中借用一个连接来执行操作并将其释放到池中。如果使用 Vert.x 运行,可以将 vertx 实例传递给它:
SqlClient client = PgPool.client(vertx, connectOptions, poolOptions);当不再使用它时,需要释放客户端:
client.close();要在同一个连接上执行多个操作时,需要从池中获取一个 connection:
// 创建池化客户端
PgPool pool = PgPool.pool(vertx, connectOptions, poolOptions);
// 从池中获取一个连接
pool.getConnection().compose(conn -> {
System.out.println("从池中得到连接");
// 所有的操作均在同一个连接中执行
return conn
.query("SELECT * FROM users WHERE id='julien'")
.execute()
.compose(res -> conn
.query("SELECT * FROM users WHERE id='1'")
.execute())
.onComplete(ar -> {
// 完成后将其放回连接池
conn.close();
});
}).onComplete(ar -> {
if (ar.succeeded()) {
System.out.println("完成");
} else {
System.out.println("发生错误 " + ar.cause().getMessage());
}
});完成连接后,必须将其关闭以将其释放到池中,以便可以重用它。
执行 SQL
当不需要事务或执行单个查询时,可以直接在池上运行查询,池将使用一个连接运行查询并将结果返回。以下是运行简单查询的方法:
client
.query("SELECT * FROM users WHERE id='julien'")
.execute(ar -> {
if (ar.succeeded()) {
RowSet<Row> result = ar.result();
System.out.println("获取到 " + result.size() + " 行 ");
} else {
System.out.println("失败: " + ar.cause().getMessage());
}
client.close(); // 释放连接
});Prepared Query
Prepared Query 和 jdbc 中的 Prepared Statement 类似。vertx-pg-client 允许对准备好的查询执行相同的操作。SQL 字符串可以按位置引用参数,使用数据库语法 $1、$2 等:
client
.preparedQuery("SELECT * FROM users WHERE id=$1")
.execute(Tuple.of("julien"), ar -> {
if (ar.succeeded()) {
RowSet<Row> rows = ar.result();
System.out.println("获取到 " + rows.size() + " 行 ");
} else {
System.out.println("失败: " + ar.cause().getMessage());
}
});RowSet 查询方法提供了一个适用于 SELECT 查询的异步实例:
client
.preparedQuery("SELECT first_name, last_name FROM users")
.execute(ar -> {
if (ar.succeeded()) {
RowSet<Row> rows = ar.result();
for (Row row : rows) {
System.out.println("User " + row.getString(0) + " " + row.getString(1));
}
} else {
System.out.println("失败: " + ar.cause().getMessage());
}
});更多使用方法及高级特性请移步 官方文档。
简单封装
在实际项目当中,更倾向于使用一个类进行管理,并且尽可能使用连接池,它在初始化时将一定量的连接对象放到连接池中,需要时直接从连接池中取出空闲对象,使用完毕后不释放掉对象,而是放回到连接池中以便下一次复用。从而降低创建连接对象带来的延迟,提高系统性能。因此我们新建一个 PgsqlDb 类:
/**
* 将数据库查询得到的结果转换为 json
*
* @param rows 数据库查询结果集合
*/
public static JsonArray parseJsonArray(RowSet<Row> rows) {
JsonArray json = new JsonArray();
List<String> columns = rows.columnsNames();
rows.forEach(row -> {
JsonObject rowJson = new JsonObject();
for (String col : columns) {
rowJson.put(col, row.getValue(col));
}
json.add(rowJson);
});
return json;
}使用 kotlin
未完待续...
总结
初步使用体验:
- 官方的在线工具生成的代码有时不能直接运行,有些需要小调整,有些得自行添加;
- 没有
Spring中mvc,dao等等之类的概念,而是Verticle、router; - 目前为止像
Mybatis之类的orm,数据库相关的操作需要自己封装,用惯了orm框架,vert.x官方也只是把jdbc封装成异步; - 如果和
SpringBoot相比,Vert.x的封装度还是特别浅的,是HttpResponse级别的,vert.x需要开发者自己写的业务逻辑代码要多得多; - 对含有中文的
json接口需要手动改content-type为utf-8编码; - 目前
vert.x的生态没有Spring的好,能搜到的问题远没有像SpringBoot的那么多; - 打包体积倒是小了很多,体积在
6.16MB以上(当然正式项目的打包体积会随着依赖的增加而增加),本人使用的SpringBoot项目打包之后通常在35Mb以上; - 但是第一次打包可能会遇到问题,不像
SpringBoot那样顺利(例如需要先关掉运行中的主类); - 和
swagger-ui等在SpringBoot中常用的一些库的整合不方便,在SpringBoot中只需要加入一个依赖;
用 Vert.X 来构造系统中有高并发要求的微服务,其它复杂或者是没什么要求的部分还是采取传统方案。
我还看到有 Nutz(国人开发)、Quarkus、Javalin、Micronaut 等等后端框架,其中有些框架概念和 Spring 比较相似,用来开发快速或者追求更高的性能还是不错的,只是简单看了下文档,先暂时不上手了,内容都挺多的 😂。
相关项目
Vert.x 引入 Swagger: vertx-auto-swagger
Vert.x 使用 PgSQL: vertx-postgresql-starter